So Anthropic dropped Claude Opus 4.8 on May 28, 2026. Forty-one days after 4.7. That’s fast like, unusually fast for Anthropic. And I think the quick turnaround says more about what went wrong with 4.7 than Anthropic would like to admit.
But before I get into that, let me say the obvious thing: 4.8 looks good. Like, actually good, not in a “PR benchmarks look nice” way. The coding numbers went from 64.3% to 69.2% on SWE-bench Pro. The math jump is kind of wild — 96.7% on USAMO 2026, up from 69.3% on 4.7. That’s a huge jump in one cycle. There’s also a new feature called Dynamic Workflows that lets Claude Code spin up parallel subagents, so you can basically throw a big codebase migration at it and let it run. I haven’t tried this yet but the idea alone is interesting.

Same price as 4.7. $5 per million input tokens, $25 per million output. And fast mode which used to cost $30/$150 is now $10/$50. That’s actually a meaningful price cut on the fast side.
But here’s what I keep thinking about. While 4.8 is shipping and looking fine, a lot of people myself included have been feeling like older versions of Claude quietly got worse. Not overnight. More like slowly, the way a car starts running rough and you can’t tell exactly when it started.
What Actually Happened With Older Claude
I want to be careful here because I don’t fully understand all of it. But I do know I was using Claude Opus 4.6 and Sonnet 4.6 heavily for writing and some light coding stuff, and sometime around late February or early March 2026, it started feeling… off. Slower to think through things. More likely to give me the “easy answer” instead of the right answer.
At first I thought it was me. Maybe I was prompting it differently. Maybe I was tired and reading it wrong.
Turns out it wasn’t just me.
An AMD senior director named Laurenzo filed a GitHub issue on April 2 with telemetry from 6,852 Claude Code sessions showing a measurable drop in performance. Not vibes actual data. The post reportedly read less like a complaint and more like a criminal investigation, and honestly, from what I read of it, that description fits.
What Anthropic confirmed, through Claude Code lead Boris Cherny, is that three product changes happened between February and March 2026. On February 9, Opus 4.6 was switched to “adaptive thinking” by default, meaning the model decides how much to reason per task instead of using a fixed reasoning budget. On March 3, the default effort level was dropped to “medium” — specifically effort level 85. And on February 12, intermediate thinking was hidden from the UI to reduce latency, though Anthropic says this didn’t affect the actual thinking process underneath.
The official explanation is that these were deliberate cost and latency tradeoffs. The developer experience, according to a lot of people who wrote about it, felt like the model suddenly “thought less” and produced worse work. One person described it as “dumber than Sonnet 3.5.” That’s pretty rough if you’re paying for Opus.
And it gets a bit messier. A Techmaniacs investigation from April 17 also pointed to actual infrastructure bugs. In August-September 2025, Anthropic published a postmortem confirming that requests were getting misrouted to servers with different context window configs, there was some output corruption from a misconfigured TPU server, and a compiler bug was causing the model to exclude its highest-probability tokens during generation. This stuff was happening for weeks before Anthropic caught it and fixed it. So some of the “Claude got dumber” feeling was genuinely the model being broken at the infrastructure level.
So it’s not one thing. It’s infrastructure bugs plus deliberate defaults changes plus load issues during peak hours. All overlapping, all happening around the same time.
The Thing That Actually Annoys People
Here’s what I think is the real issue, and it’s less about the technical specifics and more about trust.
When you pay for a flagship model and then, without any announcement, the defaults get changed in a way that makes it think less and respond faster — that feels like a quiet downgrade. Even if the model weights are technically identical. Even if the change is reversible. Even if Anthropic believes it’s the right balance for “most users.”
Most users didn’t consent to being the baseline.
The VentureBeat report from April noted that Anthropic told Team and Enterprise customers they weren’t affected by the effort-level changes. Fine. But Pro users on Cowork and Claude Desktop couldn’t even change the default — only Claude Code terminal users could manually type /effort high to get the full reasoning back. That's a pretty big gap in who gets the real product.
I want to be fair: Anthropic has publicly said it does not intentionally degrade its models. And based on the actual technical evidence, I believe that. The bugs were real. The tradeoffs were cost-driven, not malicious. But “not intentional” and “not frustrating” are two different things. Developers who built workflows around a certain behavior level and then saw those workflows break — they’re not being unreasonable.
The Fortune article from April 24 described the weeks-long performance decline and Anthropic’s slow response as “testing developer loyalty” at a critical time. The company’s annualized revenue is around $30 billion now. A lot of that comes from developers who trust Claude Code. Losing that trust over something that felt like a stealth change — even if it technically wasn’t — is a real business problem, not just a Reddit complaint.
So Does 4.8 Fix Any of This?
Partly, I think.
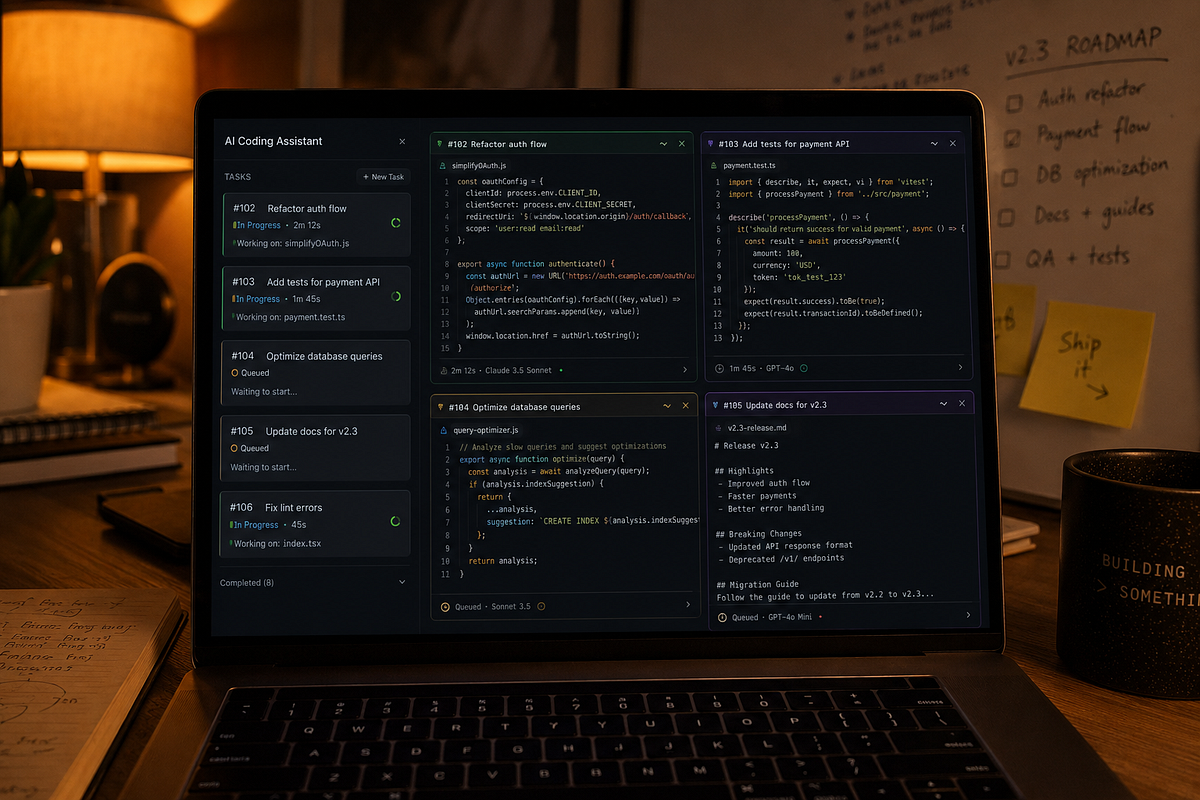
The effort control feature is actually a direct response to the backlash. Now all claude.ai users can set how much effort Claude puts into a response. This should have existed before, honestly. It’s the kind of thing where you wonder why it took a public complaint backed by 6,852 sessions to make it happen, but okay, at least it’s here.
Dynamic Workflows is available on Max, Team, and Enterprise plans for now. If you’re on Pro basic, you can’t use it yet. The parallel subagent thing is genuinely new — it’s not just about running one task well, it’s about running hundreds of tasks in parallel with an orchestrator model merging the results. For large codebase work this could be a real shift. We’ll see how it handles edge cases once more people are actually running it in production. Right now it’s early.
The honesty improvements are also interesting. Anthropic says Opus 4.8 is four times less likely to let flaws in its own code pass without flagging them. I tested this briefly with some deliberately broken functions and it did call out the issues more clearly than 4.7 was doing. Not a huge sample size but it felt different.
And fast mode is now $10/$50 per million tokens instead of $30/$150. That’s actually a good deal. Three times cheaper for 2.5x speed — if your workflow works at that speed, this makes a lot more sense economically.
Is The “Getting Dumber” Feeling Real Or Not
Both, basically.
Some of it was infrastructure bugs that are now fixed — the September 2025 routing issues, the TPU compiler bug. Real, documented, temporary. Some of it was deliberate default changes that made the model reason less in exchange for speed and cost savings. Real, documented, but reversible if you know where to look. And some of it is just the natural thing that happens when a new model releases and the previous one gets less attention and optimization effort.
There’s also something more subtle that I can’t fully explain. When you use a model a lot, you build a sort of mental model of how it thinks. You develop prompting habits that work. And when the model changes, even slightly, those habits stop working as well. It feels like the model got worse because your prompts are producing worse outputs. But really what happened is the model changed and your muscle memory didn’t.
I’ve noticed this with my own usage. Prompts that worked great in November were producing mediocre results in March. Some of that was the effort-level defaults. Some of it was context rot from long sessions — Anthropic acknowledges that long conversations reduce output quality as the context fills up. Starting fresh sessions every 30–45 minutes helps more than I expected.
The thing is, 4.8 does actually feel better for coding tasks to me. Like I said, not a scientific test. But the quality I was getting from 4.6 before all the changes — I think I’m getting closer to that now again, just with a newer model. Whether that’s 4.8 being genuinely better or just the defaults being more sane now, I honestly can’t tell.
What I’m Actually Watching For
Sonnet 4.8 is supposedly coming soon. So is Mythos 1 as a public release — Anthropic mentioned broader availability in June-July 2026. Mythos is currently in limited preview for cybersecurity work and is apparently more capable than Opus 4.8 by a significant margin. Once that’s publicly accessible, the comparison landscape changes.
The thing nobody has a clean answer to yet: does Dynamic Workflows actually hold up when you throw a real production codebase at it? Early reports are cautiously positive. But the feature has been out for three days. The real test is in two or three months when people have actually beaten it up a bit.
Also — and this is just a hunch — I think Anthropic knows that rapid release cycles create their own trust problem. 4.7 was out for 41 days before 4.8 replaced it. If you built a workflow specifically tuned to 4.7 behavior, that’s a pretty short window. At some point fast iteration and stable APIs are going to be in direct conflict, and how Anthropic handles that is going to matter a lot to the people who are betting their products on this model.
For now, 4.8 is worth switching to if you’re on Opus. The price is the same, the performance is better, and the effort control finally gives you back the lever that quietly got taken away in March.