Big Data Analytics is a technology where we deal with huge amounts of data and get the necessary information from it. Hadoop is one of the most used Analytics tools which helps us in doing so.



What is Big Data Analytics?
Before understanding big data analytics, let's what the need for it is. At present days there are several sources of information like business documents, archives, employee information, etc, which come under internal sources and also external sources like social media, sensor data, news reports, survey forms, etc. This Data can be used to get necessary information about the business insights and helps in decision making. But the data can be in 100-1000gbs of data and even reach a few terra bytes. In 21's century, it's all about information, The person which the right information at right time will lead the world, And achieving this information can give a chance of getting a competitive edge over the business competitors.
Big data is considered to have 3 Main Attributes so-called the 3v's which are volume, variety, and velocity. The volume describes the amount of data, Velocity tells how fast the data is being produced, and variety tells how variant the data is and what are the different types of data formats and information available in the data. Big data doesn't deal with a single type of data format we need to be working with different schemas. There are also many traditional ways of dealing with this data like data warehousing etc, which were very revolutionary during the early days of big data analytics.
What is Hadoop?
Handling this amount of data manually is really a tedious task and processing it might take a hell of a time. This is where Hadoop comes into the picture it is an open source software framework for managing and storing big data. It was developed By Apache. It uses different technologies like parallel processing, and distributed computing to achieve it. The Hadoop framework mainly has 3 main components. They are.
- Hadoop Distributed File System (HDFS)
- Hadoop MapReduce
- YARN (Yet Another Resource Negotiator)
Hadoop Distributed File System.
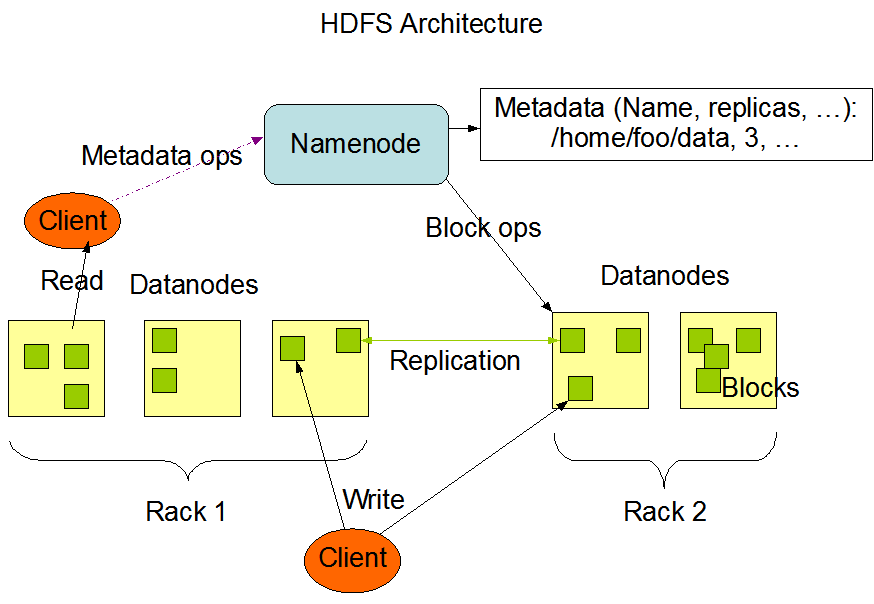
For business, we need to store large amounts of data nearly ranging from 100-1000 terra bytes and even more, and it becomes really a hard task to work with such amounts of data. Hadoop uses the distributed system to make this process simple. HDFS has 2 components Namenode and Datanode, or we can call them master and slave node. There can be many slaves but only one master node or Namenode. The Namenode is responsible for the proper working of Datanodes, it monitors the usage and working of slave nodes. The Namenode needs to have proper hardware as it has the information about all other slave nodes, and the hardware should be more like the main memory rather than secondary memory, Good secondary memory is needed in slave nodes as it is where the actual data is stored.
Let's understand this process by a simple example, Suppose we got a new dataset in the range of 100TB now this data is given to Hadoop, and the master node divides the data into different blocks of equal size, let's say 10TB each and stored in the Datanodes, but one more thing to remember here is that we not only store 10 different Datanodes but also they copy which is called as the replication factor. If the replication factor is 2, then there are more than 2 same blocks for each block, in this case, it will be 10*(1+2) so the no of blocks is not 10 but it's 30, as the replication factor is 2, we can change this value as our needs. The use of this in case of any faults or crashes we can cover from these blocks.
Whenever we need to perform some operation on the data, the Namenode has the information of all data and their locations and we can perform operations like reading, writing, updating, etc.
Hadoop MapReduce
Map-reduce is like the processing unit of the Hadoop framework. As we know that we are dealing with huge amounts of data and this data is being fragmented or distributed among the data nodes, so MapReduce helps in fragmenting these blocks. It has two components JobTracker and TaskTracker. The JobTracker is operating from the master node, whenever there is a request it distributes the request among the blocks or clusters, it also monitors the proper working of TaskTracker and data nodes, and it receives requests from the client via the MapReduce. When a client wants a particular operation it is given to the JobTracker then it distributes the task to Tasktracker and finally gets the information from different clusters and returns the result to the client.
The TaskTracker operates in the clusters, the job of it is to process the request which is given by the JobTracker. Among both of them, JobTracker is an important component as the crashing of JobTracker can affect the working of other clusters, and the TaskTracker can't function properly without it.
Yet Another Resource Negotiator (YARN)
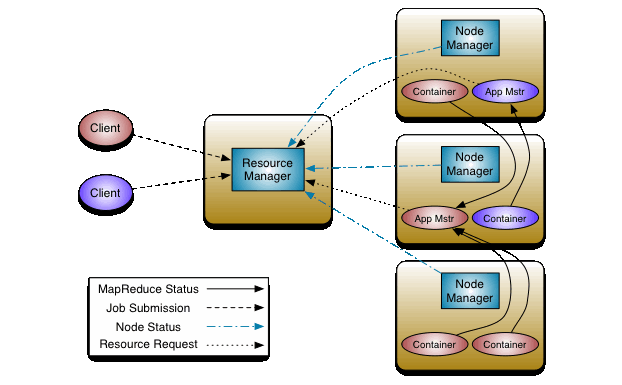
YARN was not present in the earlier versions of Hadoop it was introduced in 2.0+, adding it made Hadoop more functional and provides multitasking and job scheduling. We saw that TaskTracker worked as an interface between the client and nodes which made it more like narrowing the functionality and client requests will be dependent on the working of JobTracker. It has three components Resource Manager which allocates resources across the clusters and data anodes, Node Manager which manages the nodes creating nodes, processing using them, destroying or terminating nodes, etc, Application Manager which gives instructions to the Node Manager for creating and terminating the nodes for processing the data.